|
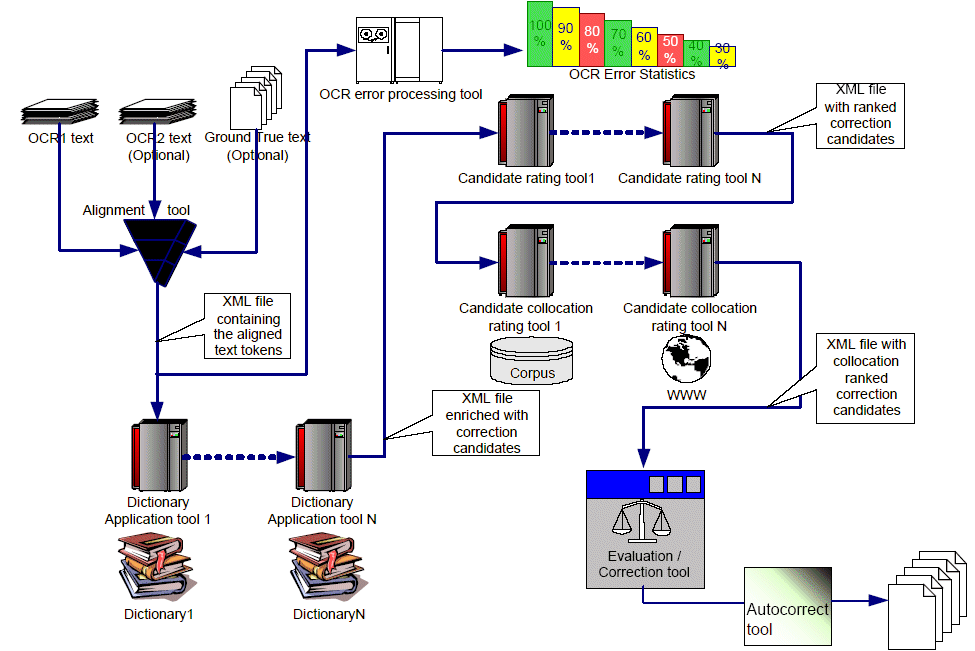
Project Tools The team has developed a very flexible architecture for OCR Correction system. The main idea is to construct a correction pipeline, where the data presented in
an uniform XML format is processed by a pipe of specific tools. Initially the XML data is derived from the OCR-ed text and afterward on each step the data is enriched with additional elements by each of the tools. At
the end the data is evaluated and the corresponding correction result is given as output. The diagram below presents the scheme of the OCR correction pipeline.. |